[Django] Test
좋은 코드란 무엇인가
- 읽기 쉬운 코드
- 중복이 없는 코드
-
테스트가 용이한 코드
- 테스트가 용이한 코드는 직접 경험해보지 못해서 어떤느낌인지 아직 모르겠다
- (이 부분이 이해가면 기록해놓자)(수정필요기록태그)
- 내가 생각하는 읽기 쉬운 코드는 최소한 변수명이나 클래스명에 대해 직관적으로 알 수 있게 작명하는거라고 생각한다.
- 그리고 귀찮더라도 간략한 설명이나 변수가 어떤걸 의미하는지 잘 써놔야 나중에 보거나 다른 사람이 봤을 때 시간 절약이 가능하다고 생각하고 이는 생산성 향상으로 이루어진다고 생각한다.
- 또한 다른 사람들의 피드백에 항상 귀 기울여야 이런 부분이 잘 반영된다고 생각한다. 물론 아무런 기준 없이 무조건 다 받아들이는 것도 문제가 된다. 이런 부분은 경험이 쌓이고 바꾸고자 하는 의지가 있다면 알잘딱깔센 될거라고 생각한다.
객체 지향 프로그래밍
- 해당부분이 맨날 나오기도하고 이제 면접도 준비할겸 정리해보았다.
OOP 는 Object Oriented Programming 를 뜻한다. 개인적으로 자바나 파이썬으로 코드를 작성할 때 클래스를 만들어서 템플릿 비슷하게 사용하는데 이게 OOP 아닌가 생각했었다. 좀 더 자세히 알아보니 사람들이 이야기하는 OOP란 객체 단위로 코드를 나눠 작성하고 이 때문에 디버깅 및 유지보수가 용이하며 이러한 이점 때문에 데이터 모델링시 객체와 매핑하는 것이 수월해지기 때문에 보다 요구사항을 명확하게 파악하여 프로그래밍 할 수 있다고 말한다.
객체 간의 정보 교환이 모두 메시지 교환을 통해 일어나므로 실행 시스템에 많은 overhead 가 발생하게 된다. 하지만 이것은 하드웨어의 발전으로 많은 부분 보완되었다.
overhead : 어떤 처리를 하기 위해 들어가는 간접적인 처리시간 , 메모리등을 말한다.
객체 지향 프로그래밍의 치명적인 단점은 함수형 프로그래밍 패러다임의 등장 배경을 통해서 알 수 있다. 바로 객체가 상태를 갖는다는 것이다. 변수가 존재하고 이 변수를 통해 객체가 예측할 수 없는 상태를 갖게 되어 애플리케이션 내부에서 버그를 발생시킨다는 것이다. 이러한 이유로 함수형 패러다임이 주목받고 있다.
이게 뭔소린가 해서 객체지향 프로그래밍의 장단점을 갖고 와봤다. 출처 장점 재사용성 -> 상속을 통해 프로그래밍시 코드의 재사용을 높일 수 있음 생산성 향상 -> 잘 설계된 클래스를 만들어서 독립적인 객체를 사용함으로써 개발의 생산성을 향상시킬 수 있음 자연적인 모델린 -> 우리 일상생활 모습의 구조가 객체에 자연스럽게 녹아들어 있기 때문에 생각하고 있는 것을 그대로 자연스럽게 구현할 수 있다. 유지보수의 우수성 -> 프로그램 수정시 추가, 수정을 하더라도 캡슐화를 통해 주변 영향이 적다. 이 때문에 유지보수가 쉬워서 매우 경제적이라 할 수 있다. 단점 개발속도가 느리다. -> 객체가 처리하는 것에 대한 정확한 이해가 필요하기 때문에 설계단계부터 많은 시간이 소모된다. 실행속도가 느린점 -> 객체지향언어는 대체적으로 실행속도가 느리다. 코딩 난이도 상승 -> 다중 상속이 지원되는 C++ 같은 경우에 너무 복잡해져 코딩의 난이도가 상승할 수 있다.
위에 나오는 캡슐화도 자바에서 접했지만 정확히 정리할 겸 갖고 와봤다. 출처는 위와 같다. 캡슐화 -> 데이터와 코드의 형태를 외부로부터 알 수 없게 하고, 데이터의 구조와 역할, 기능을 하나의 캡슐형태로 만드는 방법이다. 자바는 데이터 변수를 거의다 이 캡슐화로 사용한다. 파이썬은 튜플이 그나마 제일 비슷하다고 생각한다.
객체 지향적 설계 원칙
- SRP(Single Responsibility Principle) : 단일 책임 원칙
클래스는 단 하나의 책임을 가져야 하며 클래스를 변경하는 이유는 단 하나의 이유이어야 한다. - OCP(Open-Closed Principle) : 개방-폐쇄 원칙
확장에는 열려 있어야 하고 변경에는 닫혀 있어야 한다. - LSP(Liskov Substitution Principle) : 리스코프 치환 원칙
상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다. - ISP(Interface Segregation Principle) : 인터페이스 분리 원칙
인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다. - DIP(Dependency Inversion Principle) : 의존 역전 원칙
고수준 모듈은 저수준 모듈의 구현에 의존해서는 안된다.
RESTful API
우선, 위키백과의 정의를 요약해보자면 다음과 같다.
월드 와이드 웹(World Wide Web a.k.a WWW)과 같은 분산 하이퍼미디어 시스템을 위한 소프트웨어 아키텍처의 한 형식으로 자원을 정의하고 자원에 대한 주소를 지정하는 방법 전반에 대한 패턴
REST란, REpresentational State Transfer 의 약자이다. 여기에 ~ful 이라는 형용사형 어미를 붙여 ~한 API 라는 표현으로 사용된다. 즉, REST 의 기본 원칙을 성실히 지킨 서비스 디자인은 ‘RESTful’하다라고 표현할 수 있다.
REST가 디자인 패턴이다, 아키텍처다 많은 이야기가 존재하는데, 하나의 아키텍처로 볼 수 있다. 좀 더 정확한 표현으로 말하자면, REST 는 Resource Oriented Architecture 이다. API 설계의 중심에 자원(Resource)이 있고 HTTP Method 를 통해 자원을 처리하도록 설계하는 것이다.
나는 RESTful API 이라는 개념이 단순히 API를 만들 때 JSON과 같은 규칙정도로 이해하고 있었다. 근데 보니까 좀 더 근본적인 개념의 설계 이념이 있다.
REST 6 가지 원칙
- Uniform Interface
- Stateless
- Caching
- Client-Server
- Hierarchical system
- Code on demand
cf) 보다 자세한 내용에 대해서는 Reference 를 참고해주세요.
RESTful 하게 API 를 디자인 한다는 것은 무엇을 의미하는가.(요약)
- 리소스 와 행위 를 명시적이고 직관적으로 분리한다.
- 리소스는
URI로 표현되는데 리소스가 가리키는 것은명사로 표현되어야 한다. - 행위는
HTTP Method로 표현하고,GET(조회),POST(생성),PUT(기존 entity 전체 수정),PATCH(기존 entity 일부 수정),DELETE(삭제)을 분명한 목적으로 사용한다.
- Message 는 Header 와 Body 를 명확하게 분리해서 사용한다.
- Entity 에 대한 내용은 body 에 담는다.
- 애플리케이션 서버가 행동할 판단의 근거가 되는 컨트롤 정보인 API 버전 정보, 응답받고자 하는 MIME 타입 등은 header 에 담는다.
- header 와 body 는 http header 와 http body 로 나눌 수도 있고, http body 에 들어가는 json 구조로 분리할 수도 있다.
MIME 타입이 무슨 소리인지 몰라서 찾아봤는데 MIME 타입이란 클라이언트에게 전송된 문서의 다양성을 알려주기 위한 메커니즘이라고 한다. 출처 웹에서 파일의 확장자는 의미가 없으므로 문서와 함께 올바른 MIME 타입을 전송하도록, 서버를 정확히 설정하는 것이 중요하다. 브라우저들은 리소스를 내려받았을 때 해야 할 기본 동작이 무엇인지를 결정하기 위해 대게 MIME 타입을 사용한다고 한다.
- API 버전을 관리한다.
- 환경은 항상 변하기 때문에 API 의 signature 가 변경될 수도 있음에 유의하자.
- 특정 API 를 변경할 때는 반드시 하위호환성을 보장해야 한다.
- 서버와 클라이언트가 같은 방식을 사용해서 요청하도록 한다.
- 브라우저는 form-data 형식의 submit 으로 보내고 서버에서는 json 형태로 보내는 식의 분리보다는 json 으로 보내든, 둘 다 form-data 형식으로 보내든 하나로 통일한다.
- 다른 말로 표현하자면 URI 가 플랫폼 중립적이어야 한다.
어떠한 장점이 존재하는가?
- Open API 를 제공하기 쉽다
- 멀티플랫폼 지원 및 연동이 용이하다.
- 원하는 타입으로 데이터를 주고 받을 수 있다.
- 기존 웹 인프라(HTTP)를 그대로 사용할 수 있다.
단점은 뭐가 있을까?
- 사용할 수 있는 메소드가 한정적이다.
- 분산환경에는 부적합하다.
- HTTP 통신 모델에 대해서만 지원한다.
위 내용은 간단히 요약된 내용이므로 보다 자세한 내용은 다음 Reference 를 참고하시면 됩니다 :)
Reference
- 우아한 테크톡 - REST-API
- REST API 제대로 알고 사용하기 - TOAST
- 바쁜 개발자들을 위한 RESTFul api 논문 요약
- REST 아키텍처를 훌륭하게 적용하기 위한 몇 가지 디자인 팁 - spoqa
TDD
TDD 란 무엇인가
Test-Driven Development(TDD)는 매우 짧은 개발 사이클의 반복에 의존하는 소프트웨어 개발 프로세스이다. 우선 개발자는 요구되는 새로운 기능에 대한 자동화된 테스트케이스를 작성하고 해당 테스트를 통과하는 가장 간단한 코드를 작성한다. 일단 테스트 통과하는 코드를 작성하고 상황에 맞게 리팩토링하는 과정을 거치는 것이다. 말 그대로 테스트가 코드 작성을 주도하는 개발방식인 것이다.
Add a test
테스트 주도형 개발에선, 새로운 기능을 추가하기 전 테스트를 먼저 작성한다. 테스트를 작성하기 위해서, 개발자는 해당 기능의 요구사항과 명세를 분명히 이해하고 있어야 한다. 이는 사용자 케이스와 사용자 스토리 등으로 이해할 수 있으며, 이는 개발자가 코드를 작성하기 전에 보다 요구사항에 집중할 수 있도록 도와준다. 이는 정말 중요한 부분이자 테스트 주도 개발이 주는 이점이라고 볼 수 있다.
Run all tests and see if new one fails
어떤 새로운 기능을 추가하면 잘 작동하던 기능이 제대로 작동하지 않는 경우가 발생할 수 있다. 더 위험한 경우는 개발자가 이를 미처 인지하지 못하는 경우이다. 이러한 경우를 방지하기 위해 테스트 코드를 작성하는 것이다. 새로운 기능을 추가할 때 테스트 코드를 작성함으로써, 새로운 기능이 제대로 작동함과 동시에 기존의 기능들이 잘 작동하는지 테스트를 통해 확인할 수 있는 것이다.
Refactor code
‘좋은 코드’를 작성하기란 정말 쉽지가 않다. 코드를 작성할 때 고려해야 할 요소가 한 두 가지가 아니기 때문이다. 가독성이 좋게 coding convention 을 맞춰야 하며, 네이밍 규칙을 적용하여 메소드명, 변수명, 클래스명에 일관성을 줘야하며, 앞으로의 확장성 또한 고려해야 한다. 이와 동시에 비즈니스 로직에 대한 고려도 반드시 필요하며, 예외처리 부분 역시 빠뜨릴 수 없다. 물론 코드량이 적을 때는 이런 저런 것들을 모두 신경쓰면서 코드를 작성할 수 있지만 끊임없이 발견되는 버그들을 디버깅하는 과정에서 코드가 더럽혀지기 마련이다.
이러한 이유로 코드량이 방대해지면서 리팩토링을 하게 된다. 이 때 테스트 주도 개발을 통해 개발을 해왔다면, 테스트 코드가 그 중심을 잡아줄 수 있다. 뚱뚱해진 함수를 여러 함수로 나누는 과정에서 해당 기능이 오작동을 일으킬 수 있지만 간단히 테스트를 돌려봄으로써 이에 대한 안심을 하고 계속해서 리팩토링을 진행할 수 있다. 결과적으로 리팩토링 속도도 빨라지고 코드의 퀄리티도 그만큼 향상하게 되는 것이다. 코드 퀄리티 부분을 조금 상세히 들어가보면, 보다 객체지향적이고 확장 가능이 용이한 코드, 재설계의 시간을 단축시킬 수 있는 코드, 디버깅 시간이 단축되는 코드가 TDD 와 함께 탄생하는 것이다.
어차피 코드를 작성하고나서 제대로 작동하는지 판단해야하는 시점이 온다. 물론 중간 중간 수동으로 확인도 할 것이다. 또 테스트에 대한 부분에 대한 문서도 만들어야 한다. 그 부분을 자동으로 해주면서, 코드 작성에 도움을 주는 것이 TDD 인 것이다. 끊임없이 TDD 찬양에 대한 말만 했다. TDD 를 처음 들어보는 사람은 이 좋은 것을 왜 안하는가에 대한 의문이 들 수도 있다.
의문점들
Q. 코드 생산성에 문제가 있지는 않나?
두 배는 아니더라도 분명 코드량이 늘어난다. 비즈니스 로직, 각종 코드 디자인에도 시간이 많이 소요되는데, 거기에다가 테스트 코드까지 작성하기란 여간 벅찬 일이 아닐 것이다. 코드 퀄리티보다는 빠른 생산성이 요구되는 시점에서 TDD 는 큰 걸림돌이 될 수 있다.
Q. 테스트 코드를 작성하기가 쉬운가?
이 또한 TDD 라는 개발 방식을 적용하기에 큰 걸림돌이 된다. 진입 장벽이 존재한다는 것이다. 어떠한 부분을 테스트해야할 지, 어떻게 테스트해야할 지, 여러 테스트 프레임워크 중 어떤 것이 우리의 서비스와 맞는지 등 여러 부분들에 대한 학습이 필요하고 익숙해지는데에도 시간이 걸린다. 팀에서 한 명만 익숙해진다고 해결될 일이 아니다. 개발은 팀 단위로 수행되기 때문에 팀원 전체의 동의가 필요하고 팀원 전체가 익숙해져야 비로소 테스트 코드가 빛을 발하게 되는 것이다.
아직 테스트 용이한 코드가 어떤건지 체감이 되지않는데 뭔가 제대로 이해하면 이부분을 수정해야할 거 같다 (수정필요기록태그)
Q. 모든 상황에 대해서 테스트 코드를 작성할 수 있는가? 작성해야 하는가?
세상에는 다양한 사용자가 존재하며, 생각지도 못한 예외 케이스가 존재할 수 있다. 만약 테스트를 반드시 해봐야 하는 부분에 있어서 테스트 코드를 작성하는데 어려움이 발생한다면? 이러한 상황에서 주객이 전도하는 상황이 발생할 수 있다. 분명 실제 코드가 더 중심이 되어야 하는데 테스트를 위해서 코드의 구조를 바꿔야 하나하는 고민이 생긴다. 또한 발생할 수 있는 상황에 대한 테스트 코드를 작성하기 위해 배보다 배꼽이 더 커지는 경우가 허다하다. 실제 구현 코드보다 방대해진 코드를 관리하는 것도 쉽지만은 않은 일이 된 것이다.
모든 코드에 대해서 테스트 코드를 작성할 수 없으며 작성할 필요도 없다. 또한 테스트 코드를 작성한다고 해서 버그가 발생하지 않는 것도 아니다. 애초에 TDD 는 100% coverage 와 100% 무결성을 주장하지 않았다.
Personal Recommendation
- (도서) 켄트 벡 - 테스트 주도 개발
Reference
함수형 프로그래밍
아직 저도 잘 모르는 부분이라서 정말 간단한 내용만 정리하고 관련 링크를 첨부합니다. 함수형 프로그래밍의 가장 큰 특징 두 가지는 immutable data와 first class citizen으로서의 function이다.
immutable vs mutable
우선 immutable과 mutable의 차이에 대해서 이해를 하고 있어야 한다. immutable이란 말 그대로 변경 불가능함을 의미한다. immutable 객체는 객체가 가지고 있는 값을 변경할 수 없는 객체를 의미하여 값이 변경될 경우, 새로운 객체를 생성하고 변경된 값을 주입하여 반환해야 한다. 이와는 달리, mutable 객체는 해당 객체의 값이 변경될 경우 값을 변경한다.
first-class citizen
함수형 프로그래밍 패러다임을 따르고 있는 언어에서의 함수(function)는 일급 객체(first class citizen)로 간주된다. 일급 객체라 함은 다음과 같다.
- 변수나 데이터 구조안에 함수를 담을 수 있어서 함수의 파라미터로 전달할 수 있고, 함수의 반환값으로 사용할 수 있다.
- 할당에 사용된 이름과 관계없이 고유한 구별이 가능하다.
- 함수를 리터럴로 바로 정의할 수 있다.
Reactive Programming
반응형 프로그래밍(Reactive Programming)은 선언형 프로그래밍(declarative programming)이라고도 불리며, 명령형 프로그래밍(imperative programming)의 반대말이다. 또 함수형 프로그래밍 패러다임을 활용하는 것을 말한다. 반응형 프로그래밍은 기본적으로 모든 것을 스트림(stream)으로 본다. 스트림이란 값들의 집합으로 볼 수 있으며 제공되는 함수형 메소드를 통해 데이터를 immutable 하게 관리할 수 있다.
Reference
- 함수형 프로그래밍 소개
- 반응형 프로그래밍이란 무엇인가
- What-I-Learned-About-RP
- Reactive Programming
- MS 는 ReactiveX 를 왜 만들었을까?
MVC 패턴이란 무엇인가 ? (with MTV)
MVC
MVC (모델-뷰-컨트롤러) 는 사용자 인터페이스, 데이터 및 논리 제어를 구현하는데 널리 사용되는 소프트웨어 디자인 패턴입니다. 소프트웨어의 비즈니스 로직과 화면을 구분하는데 중점을 두고 있습니다. 이러한 “관심사 분리” 는 더나은 업무의 분리와 향상된 관리를 제공합니다. MVC 에 기반을 둔 몇 가지 다른 디자인 패턴으로 MVVM (모델-뷰-뷰모델), MVP (모델-뷰-프리젠터), MVW (모델-뷰-왓에버) 가 있습니다.
MVC 소프트웨어 디자인 패턴의 세 가지 부분은 다음과 같이 설명할 수 있습니다.
- 모델: 데이터와 비즈니스 로직을 관리합니다.
- 뷰: 레이아웃과 화면을 처리합니다.
- 컨트롤러: 명령을 모델과 뷰 부분으로 라우팅합니다.
모델 뷰 컨트롤러 예시
간단한 쇼핑 리스트 앱이 있다고 상상해봅시다. 우리가 원하는 것은 이번 주에 사야할 각 항목의 이름, 개수, 가격의 목록입니다. MVC 를 사용해 이 기능의 일부를 구현하는 방법을 아래에서 설명할 것입니다.
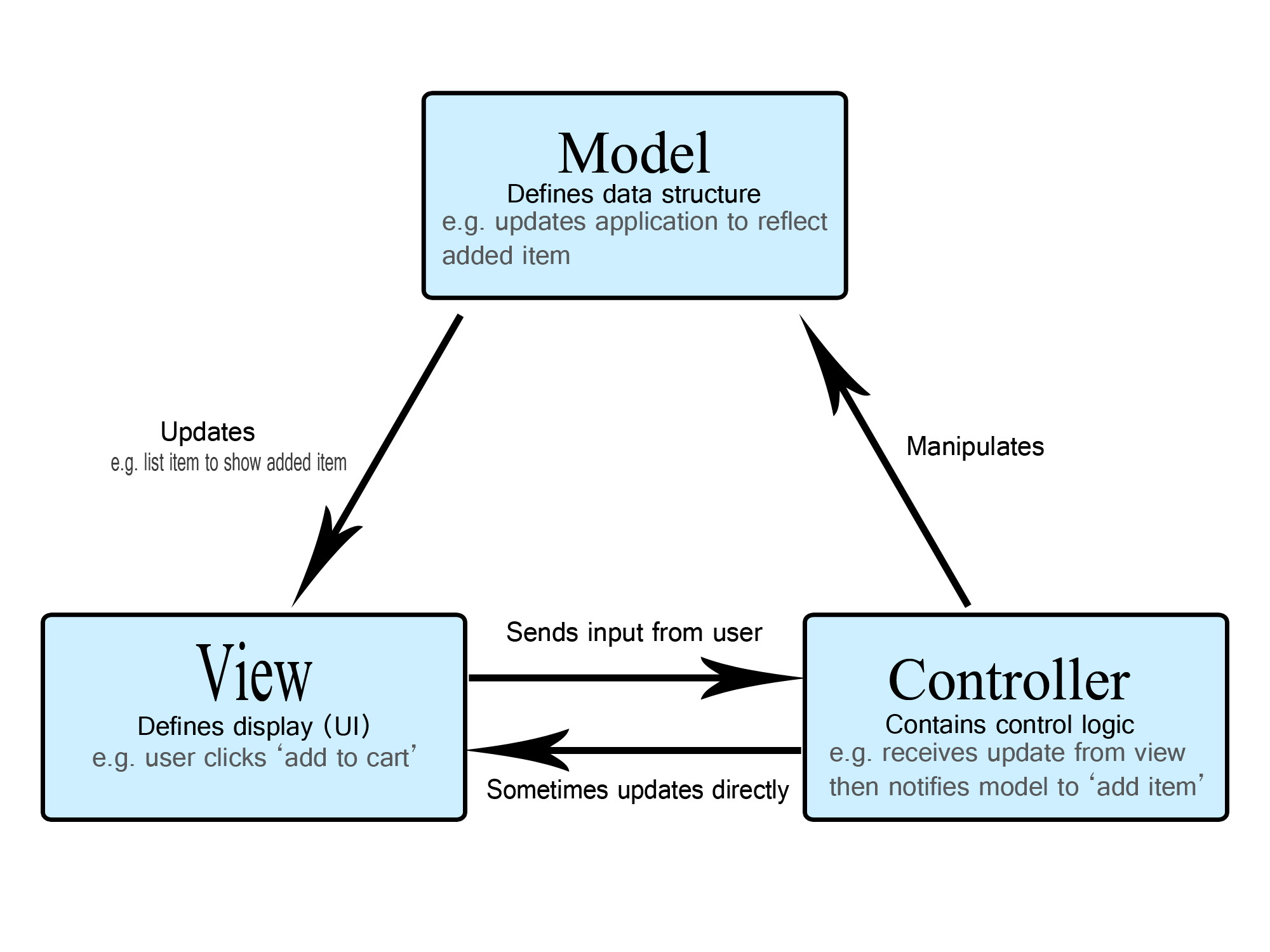
모델
모델은 앱이 포함해야할 데이터가 무엇인지를 정의합니다. 데이터의 상태가 변경되면 모델을 일반적으로 뷰에게 알리며(따라서 필요한대로 화면을 변경할 수 있습니다) 가끔 컨트롤러에게 알리기도 합니다(업데이트된 뷰를 제거하기 위해 다른 로직이 필요한 경우).
다시 쇼핑 리스트 앱으로 돌아가서, 모델은 리스트 항목이 포함해야 하는 데이터 — 품목, 가격, 등. — 와 이미 존재하는 리스트 항목이 무엇인지를 지정합니다.
뷰
뷰는 앱의 데이터를 보여주는 방식을 정의합니다.
쇼핑 리스트 앱에서, 뷰는 항목이 사용자에게 보여지는 방식을 정의하며, 표시할 데이터를 모델로부터 받습니다.
컨트롤러
컨트롤러는 앱의 사용자로부터의 입력에 대한 응답으로 모델 및/또는 뷰를 업데이트하는 로직을 포함합니다.
예를 들어보면, 쇼핑 리스트는 항목을 추가하거나 제거할 수 있게 해주는 입력 폼과 버튼을 갖습니다. 이러한 액션들은 모델이 업데이트되는 것이므로 입력이 컨트롤러에게 전송되고, 모델을 적당하게 처리한다음, 업데이트된 데이터를 뷰로 전송합니다.
단순히 데이터를 다른 형태로 나타내기 위해 뷰를 업데이트하고 싶을 수도 있습니다(예를 들면, 항목을 알파벳순서로 정렬한다거나, 가격이 낮은 순서 또는 높은 순서로 정렬). 이런 경우에 컨트롤러는 모델을 업데이트할 필요 없이 바로 처리할 수 있습니다.
웹에서의 MVC
웹 개발자로써, 여러분이 이 패턴을 이전에 의식적으로 사용한 적이 없더라도 아마 상당히 친숙할것입니다. 여러분의 데이터 모델은 아마 어떤 종류의 데이터베이스에 포함되어있었을 것입니다(MySQL 과 같은 전통적인 서버 사이드 데이터베이스, 또는 IndexedDB 같은 클라이언트 사이드 솔루션). 여러분의 앱의 제어 코드는 아마 HTML/JavaScript 로 작성되었을 것이고, 사용자 인터페이스는 HTML/CSS 등 여러분이 선호하는 것들로 작성되었을 것입니다. 이는 MVC 와 아주 유사하게 들리지만, MVC 는 이러한 컴포넌트들이 더 엄격한 패턴을 따르도록합니다.
웹의 초창기에, MVC 구조는 클라이언트가 폼이나 링크를 통해 업데이트를 요청하거나 업데이트된 뷰를 받아 다시 브라우저에 표시하기 위해 대부분 서버 사이드에서 구현되었습니다. 반면, 요즘에는, 클라이언트 사이드 데이터 저장소의 출현과 필요에 따라 페이지의 일부만 업데이트를 허용하는 XMLHttpRequest 를 포함해 더 많은 로직이 클라이언트 사이드에 추가되었습니다.
AngularJS 및 Ember.js 와 같은 웹 프레임워크들은 약간씩은 방식이 다르지만, 모두 MVC 구조를 구현합니다.
더 알아보기
일반 지식
- 모델-뷰-컨트롤러 on Wikipedia
MVT
- MDN 에서도 소개 안되는 쩌리짱MVT.. 하지만 장고가 MVT 패턴이라고 하니 좀 더 알아보자
- MTV 는 모델, 템플릿 뷰 의 약자이며 MVC에 대응되는 장고의 디자인 패턴이다.
- 출처
MTV 패턴은 장고의 디자인 패턴입니다.
(간혹 MVT라고 부르는 분들도 계시지만 저는 MVC에 대응시키기 편하게 MTV를 사용합니다.) MTV 패턴은 명칭이 조금 다를 뿐이지 기본적인 골자는 MVC 패턴과 동일합니다. 그렇다면 왜 굳이 장고가 MTV라는 디자인 패턴을 사용할까요? 이는 MTV 패턴만의 특징이 있기 때문입니다.
Model(모델) - MVC 패턴의 모델에 대응되며 DB에 저장되는 데이터를 의미합니다. 모델은 클래스로 정의되며 하나의 클래스가 하나의 DB Table입니다. 원래 DB를 조작하기 위해선 SQL을 다룰 줄 알아야 하지만 장고는 ORM(Object Relational Mapping)기능을 지원하기 때문에 파이썬 코드로 DB를 조작할 수 있습니다.(ORM에 대해서는 추후 다루겠습니다.)
Template(템플릿) - MVC 패턴의 뷰에 대응되며 유저에게 보여지는 화면을 의미합니다. 장고는 뷰에서 로직을 처리한 후 html 파일을 context와 함께 렌더링하는데 이 때의 html 파일을 템플릿이라 칭합니다. 장고는 자체적인 Django Template 문법을 지원하며 이 문법 덕분에 html 파일 내에서 context로 받은 데이터를 활용할 수 있습니다.
View(뷰) - MVC 패턴의 컨트롤러에 대응되며 요청에 따라 적절한 로직을 수행하여 결과를 템플릿으로 렌더링하며 응답합니다. 다만 항상 템플릿을 렌더링 하는 것은 아니고 백엔드에서 데이터만 주고 받는 경우도 있습니다.
여기에 장고는 URLConf(URL 설계)라는 단계가 하나 더 있습니다. URL 패턴을 정의하여 해당 URL과 뷰를 매핑하는 단계라고 생각하시면 됩니다.
from django.urls import path
from . import views
app_name = 'project'
urlpatterns = [
path('', views.HomeView.as_view(), name='home'),
path('login/', views.LoginView.as_view(), name='login'),
]
이와 같이 path함수를 이용해 URL을 뷰와 손쉽게 매핑시킬 수 있습니다. 그림으로 정리하면 아래와 같습니다.
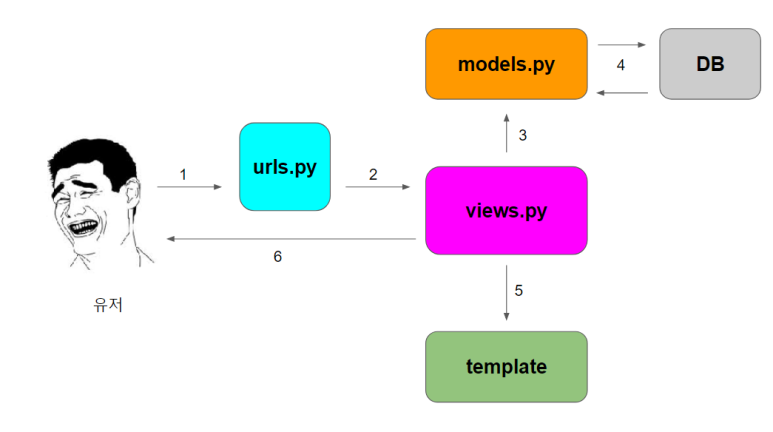
다시 말씀드리지만 유저가 이상해보이는건 착시입니다.
- 유저가 특정 url로 요청을 보냅니다.
- urlConf를 통해 해당 url과 매핑된 뷰를 호출합니다.
- 호출된 뷰는 요청에 따라 적절한 로직을 수행하며 그 과정에서 모델에게 CRUD를 지시합니다.
- 모델은 ORM을 통해 DB와 소통하며 CRUD를 수행합니다.
- 그 후 뷰는 지정된 템플릿을 렌더링하고
- 최종 결과를 응답으로 반환합니다.
장고하면 ORM이 계속 나오니 ORM도 알아보자
ORM
- 객채(Object)의 관계(Relational)를 연결(Mapper)해주는 것을 뜻한다. 객체 지향적인 방법을 사용하여 데이터베이스의 데이터를 쉽게 조작할 수 있게 해주는 것이다.
즉, Django의 ORM이란, 파이썬과 데이터베이스의 SQL사이의 통역사 역할을 해준다. 앞으로 아래의 Function을 활용하여 ORM을 완성해 갈 것입니다. 원하는 query를 만들기 위해서는 함수들을 사용해야 합니다.
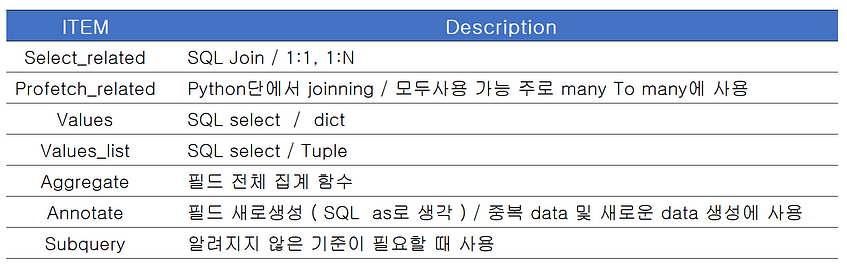
(표) ORM Function
조건 키워드
① model.objects.filter(name__contains=’Welcom’)
- ② model.objects.filter(name__icontains=’Welcom’)
-
① 문자 검색 할 수 있음 / ② 대소문자를 구분 하지 않음
ORM을 활용한 데이터 전체 불러오기
ORM을 활용한 데이터 필터
Get과 Filter 차이
- Get : 한개의 데이터를 추출 할때 사용
- Filter : 여러 개의 데이터를 추출 할때 사용

키워드 조건표
ORM을 활용한 데이터 — 정렬하기
-
[SQL 문법]
SELECT * FROM TABLE1 ORDER BY(create_date) -
[ORM 문법]
Model.objects.all().order_by(‘created_date’)
ORM을 활용한 데이터 — 평균, 최소, 최대, 합계
- View 테이블에 아래와 같이 import Code를 넣어 주지 않으면 에러가 발생할테니 꼭 넣어 주길 바랍니다.
from django.db.models import Avg, Max, Min, Sum
[SQL CODE]
SELECT COUNT(PROCESS)
FROM TABLE
GROUP BY PROCESS
[ORM CODE]
TABLE.objects.all().aggregate(Avg('PROCESS')) #평균
TABLE.objects.all().aggregate(Min('PROCESS')) #최소
TABLE.objects.all().aggregate(Max('PROCESS')) #최대
TABLE.objects.all().aggregate(Sum('PROCESS')) #합계
장고 ORM 좀 더 자세히
데이터 조회 (Read)
>>> Post.objects.all()
>>> <QuerySet [<Post: this is a test1 title>, <Post: this is a test2 title>]>
장고 ORM 요리책
『장고 ORM 요리책(Django ORM Cookbook)』은 장고의 ORM(객체 관계 매핑) 기능과 모델 기능을 활용하는 다양한 레시피(조리법)를 담은 책입니다. 장고는 모델-템플릿-뷰(MTV) 프레임워크입니다. 이 책은 그 가운데 ‘모델’에 대해 상세히 다룹니다.
이 책은 “장고 ORM/쿼리셋/모델으로 ~을 하는 방법은 무엇인가요?”와 같은 질문 50여 개와 그 답을 담고 있습니다.

정보를 조회하고 필요한 항목을 선별하는 방법
- 1. 장고 ORM이 실행하는 실제 SQL 질의문을 확인할 수 있나요?
- 2. OR 연산으로 일부 조건을 하나라도 만족하는 항목을 구하려면 어떻게 하나요?
- 3. AND 연산으로 여러 조건을 모두 만족하는 항목을 구하려면 어떻게 하나요?
- 4. NOT 연산으로 조건을 부정하려면 어떻게 하나요?
- 5. 동일한 모델 또는 서로 다른 모델에서 구한 쿼리셋들을 합할 수 있나요?
- 6. 필요한 열만 골라 조회하려면 어떻게 하나요?
- 7. 장고에서 서브쿼리 식을 사용할 수 있나요?
- 8. 필드의 값을 서로 비교하여 항목을 선택할 수 있나요?
- 9. FileField에 파일이 들어있지 않은 행은 어떻게 구할 수 있나요?
- 10. 두 모델을 결합(JOIN)하려면 어떻게 하나요?
- 11. 두번째로 큰 항목은 어떻게 구하죠?
- 12. 특정 열의 값이 동일한 항목은 어떻게 찾나요?
- 13. 쿼리셋에서 고유한 필드 값을 가진 항목은 어떻게 구하나요?
- 14. Q 객체를 이용해 복잡한 질의를 수행하는 방법은 무엇인가요?
- 15. 기록된 항목의 집계를 구할 수 있나요?
- 16. 항목을 무작위로 뽑고 싶습니다. 효율적인 방법이 있을까요?
- 17. 장고가 지원하지 않는 데이터베이스 함수를 사용할 수 있나요?
항목을 생성·갱신·삭제하는 방법
- 1. 여러 개의 행을 한번에 생성하는 방법이 있나요?
- 2. 기존에 저장된 행을 복사해 새로 저장하는 방법은 무엇인가요?
- 3. 특정 모델의 항목이 하나만 생성되도록 강제하는 방법이 있나요?
- 4. 모델 인스턴스를 저장할 때, 다른 모델에 반정규화된 필드를 함께 갱신하는 방법이 있나요?
- 5. TRUNCATE 문을 수행하는 방법이 있나요?
- 6. 모델 인스턴스가 생성·갱신될 때 발생하는 시그널에는 어떤 것이 있나요?
- 7. 시간 정보를 다른 양식으로 변환하여 데이터베이스에 저장하려면 어떻게 해야 하나요?
조회 결과를 정렬하는 방법
- 1. 쿼리셋을 오름차순/내림차순으로 정렬할 수 있나요?
- 2. 대문자·소문자를 구별하지 않고 정렬하려면 어떻게 하나요?
- 3. 여러 개의 필드를 기준으로 정렬하는 방법이 있나요?
- 4. 외래 키로 연결된 다른 표의 열을 기준으로 정렬할 수 있나요?
- 5. 계산 필드를 기준으로 정렬할 수 있나요?
모델을 정의하는 방법
- 1. 일대일 관계는 어떻게 나타내나요?
- 2. 일대다 관계는 어떻게 나타내나요?
- 3. 다대다 관계는 어떻게 나타내나요?
- 4. 모델에 자기 참조 외래 키를 정의할 수 있나요?
- 5. 기존 데이터베이스를 장고 모델로 옮길 수 있나요?
- 6. 데이터베이스 뷰에 대응하는 모델을 정의할 수 있나요?
- 7. 분류·댓글처럼 아무 모델이나 가리킬 수 있는 범용 모델을 정의할 수 있나요?
- 8. 모델에 연결된 표의 이름을 지정할 수 있나요?
- 9. 모델 필드의 데이터베이스 열 이름을 지정할 수 있나요?
- 10.
null=True와blank=True의 차이가 무엇인가요? - 11. 기본 키(PK)로 ID 대신 UUID를 사용할 수 있나요?
- 12. 슬러그 필드를 사용할 수 있나요?
- 13. 장고 프로젝트 하나에서 여러 개의 데이터베이스를 사용할 수 있나요?
장고 ORM 코드를 테스트하는 방법
- 1. 질의 횟수가 고정된 횟수만큼만 일어나는지 확인할 수 있을까요?
- 2. 데이터베이스를 재사용하여 테스트 실행 속도를 높일 수 있나요?
- 3. 모델 객체를 데이터베이스에서 다시 읽어들일 수 있나요?
댓글남기기